Part 2: Introduction to OpenMPI
DeepSquare offers a High-Performance Computing (HPC) service platform. To fully leverage its capabilities, understanding the Message Passing Interface (MPI) specifically, OpenMPI is essential. OpenMPI is a standard facilitating parallel computing across diverse processors or machines.
In this section, we'll introduce OpenMPI and its application within the DeepSquare environment. OpenMPI is designed for high performance, wide portability, scalability, and ease of use on systems ranging from small clusters to large supercomputers.
We'll guide you through the process of adapting an existing application to use OpenMPI. Remember, we're here to assist. For any questions or support, please reach out to us on our Discord server.
Adapting our "hello world" app to use OpenMPI
Our previous "hello world" workflow was:
## Allow DeepSquare logging
enableLogging: true
## Allocate resources
resources:
## A task is one process. Multiple task will allocate multiple processes.
tasks: 1
## Number of cpu physical thread per process.
cpusPerTask: 1
## Memory (MB) per cpu physical thread.
memPerCpu: 1024
## GPU (graphical process unit) for the whole job.
gpus: 0
## The job content
steps:
## The steps of the jobs which are run sequentially.
- name: 'hello-world'
run:
command: echo "hello world"
In that example, we only utilized a single task with one CPU and 1024 MB of memory.
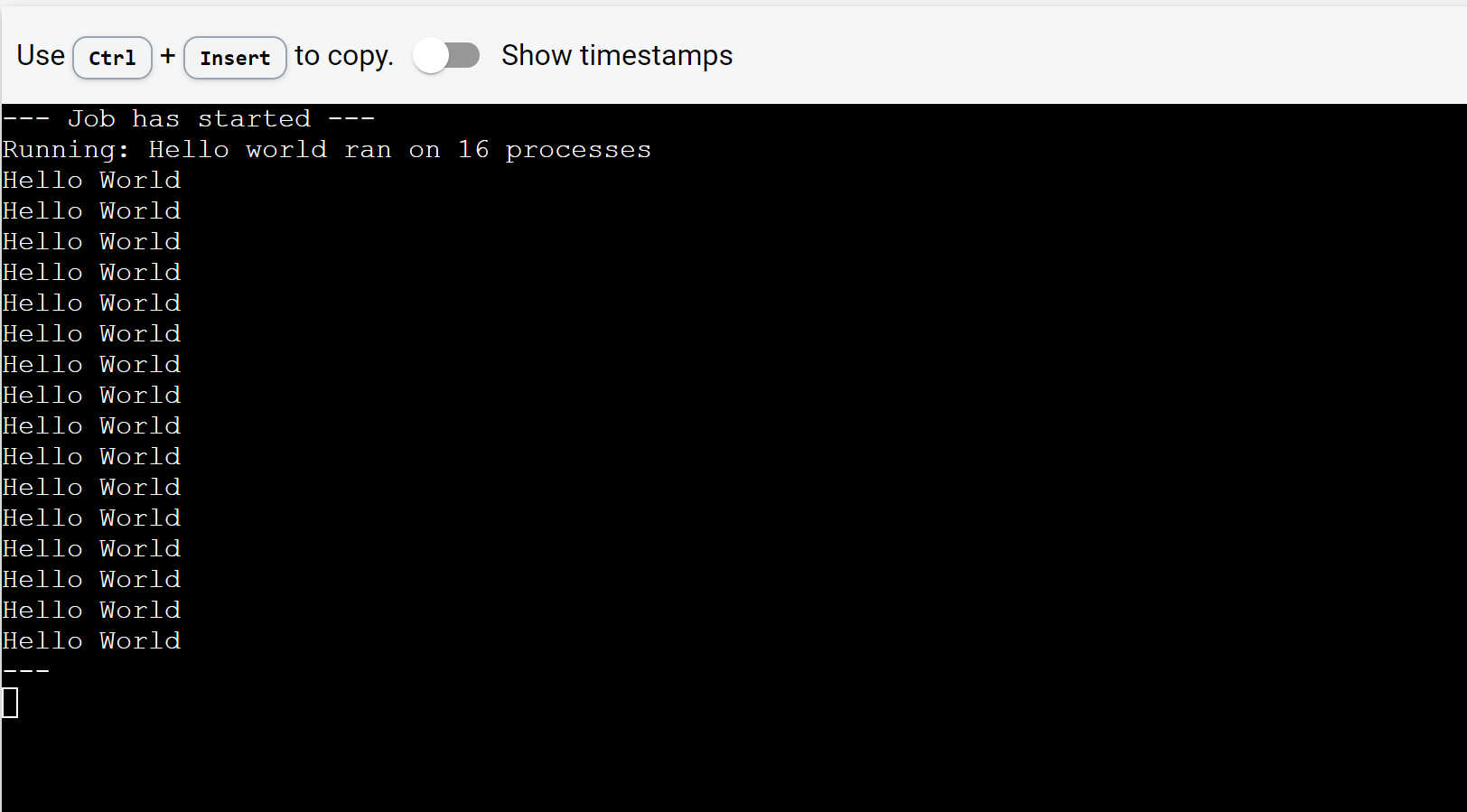
Now, we'll scale up and run parallelize the "hello world" command on 16 CPUs with the same amount of RAM per CPU as before.
Instead of echoing "Hello World" directly from the command entry, we're going to use MPI and run this command:
mpirun -np 16 echo 'Hello World'
mpirun is a command used to run MPI programs. This command is part of the OpenMPI suite of tools that facilitate parallel computing.
-
-np 16: The-npoption specifies the number of processes that thempiruncommand should start. In this case, it's set to 16 because we want to start 16 instances of the program. -
echo 'Hello World': This is the command that is being parallized.
Here is the updated workflow:
## Allow DeepSquare logging
enableLogging: true
## Allocate resources
resources:
## A task is one process. Multiple task will allocate multiple processes.
tasks: 1
## Number of cpu physical thread per process.
cpusPerTask: 1
## Memory (MB) per cpu physical thread.
memPerCpu: 1024
## GPU (graphical process unit) for the whole job.
gpus: 0
## The job content
steps:
## The steps of the jobs which are run sequentially.
- name: Hello world ran on 16 processes
run:
command: mpirun -np 16 echo 'Hello World'
However, this won't run because our infrastructure already integrates OpenMPI in the workflow API using PMIx:
- there is no need to use
mpiruncommand. - the number of tasks can replace the number of processes defined in
mpirun!
So instead, the workflow becomes:
## Allow DeepSquare logging
enableLogging: true
## Allocate resources
resources:
## A task is one process. Multiple task will allocate multiple processes.
tasks: 16
## Number of cpu physical thread per process.
cpusPerTask: 1
## Memory (MB) per cpu physical thread.
memPerCpu: 1024
## GPU (graphical process unit) for the whole job.
gpus: 0
## The job content
steps:
## The steps of the jobs which are run sequentially.
- name: Hello world ran on 16 processes
run:
command: echo 'Hello World'
resources:
## Launch 16 processes
tasks: 16
Notice the resources block within the steps block. That one is different from the resources allocation block at the start of the workflow.
Hereafter are the default behavior of the resources block in the steps block:
cpusPerTask,memPerCpuare inherited from theresources allocationblock.tasks, if not specified, set to 1 by default.gpusPerTask(which is notgpus!), if not specified, set to 0 by default.
If we don't set tasks within the steps block to 16, then we would allocate 16 tasks but only use one!
More infos about default values are specified in the API references.
In our case, the execution of the step implicitly uses 1 CPU per task, 1024 MB of memory per CPU, and no GPUs and explicitly uses 16 tasks.
You can launch it on DeepSquare Dev app to see the results!
Demonstrating OpenMPI with an MPI application
Following our previous 'Hello World' example, where we operated 16 separate processes, we're now going to explore inter-process communication with OpenMPI. This feature is crucial for high-performance computing as it enables coordinated tasks and data sharing between multiple processors.
In our next example, the application, written in C and utilizing OpenMPI, conducts a simple ring test within a distributed computing environment. The main points are as follows:
Application code
/*
* Copyright (c) 2004-2006 The Trustees of Indiana University and Indiana
* University Research and Technology
* Corporation. All rights reserved.
* Copyright (c) 2006 Cisco Systems, Inc. All rights reserved.
* Copyright (c) 2023 DeepSquare Association. All rights reserved.
*
* Simple ring test program in C.
*/
#include "mpi.h"
#include <stdio.h>
int main(int argc, char \*argv[]) {
int rank, size, next, prev, message, tag = 201;
/* Start up MPI */
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
/* Calculate the rank of the next process in the ring. Use the
modulus operator so that the last process "wraps around" to
rank zero. */
next = (rank + 1) % size;
prev = (rank + size - 1) % size;
/* If we are the "master" process (i.e., MPI_COMM_WORLD rank 0),
put the number of times to go around the ring in the
message. */
if (0 == rank) {
message = 10;
printf("rank 0 sending %d to %d, tag %d (%d processes in ring)\n", message,
next, tag, size);
MPI_Send(&message, 1, MPI_INT, next, tag, MPI_COMM_WORLD);
printf("rank 0 sent to %d\n", next);
}
/* Pass the message around the ring. The exit mechanism works as
follows: the message (a positive integer) is passed around the
ring. Each time it passes rank 0, it is decremented. When
each processes receives a message containing a 0 value, it
passes the message on to the next process and then quits. By
passing the 0 message first, every process gets the 0 message
and can quit normally. */
while (1) {
MPI_Recv(&message, 1, MPI_INT, prev, tag, MPI_COMM_WORLD,
MPI_STATUS_IGNORE);
printf("rank %d: received the message %d and is passing to the next: %d\n",
rank, message, next);
if (0 == rank) {
--message;
printf("rank 0 decremented value: %d\n", message);
}
MPI_Send(&message, 1, MPI_INT, next, tag, MPI_COMM_WORLD);
if (0 == message) {
printf("rank %d exiting\n", rank);
break;
}
}
/* The last process does one extra send to process 0, which needs
to be received before the program can exit */
if (0 == rank) {
MPI_Recv(&message, 1, MPI_INT, prev, tag, MPI_COMM_WORLD,
MPI_STATUS_IGNORE);
}
/* All done */
MPI_Finalize();
return 0;
}
- Every process, upon starting, identifies its unique ID (rank) and the total number of processes involved.
- Each process recognizes the processes directly before and after it in a looped structure.
- The master process (ID 0) starts a message with the value 10 and forwards it to the next process.
- The message cycles through the loop of processes, and each time it returns to the master, its value is reduced by 1.
- This cycle continues until the message's value reaches 0. When a process receives the 0 message, it passes it on and then stops.
- An additional receive operation is included for the master process to ensure it gets the termination message before the application ends.
The application is containerized and publicly accessible by pulling the image at ghcr.io/eepsquare-io/mpi-example:latest.
The associated workflow is:
## Allow DeepSquare logging
enableLogging: true
## Allocate resources
resources:
## A task is one process. Multiple task will allocate multiple processes.
tasks: 16
## Number of cpu physical thread per process.
cpusPerTask: 1
## Memory (MB) per cpu physical thread.
memPerCpu: 1024
## GPU (graphical process unit) for the whole job.
gpus: 0
## The job content
steps:
## The steps of the jobs which are run sequentially.
- name: Run the circle progra
run:
command: ./main
workDir: /app
resources:
## Launch 16 processes
tasks: 16
## Run in a container containing the example
container:
image: deepsquare-io/mpi-example:latest
registry: ghcr.io
In the above workflow, you'll notice that we've added a few elements:
container: This keyword initiates a container code block.image: This is the name of the container image used for the workflow, specified within thecontainerblock.registry: This specifies where the image is stored.workDir: This defines the working directory. When a container image is provided, the path is a directory within the container, relative to the root of the image file system. You can find more info about workDir here.
You can launch it on DeepSquare Dev app to see the results:
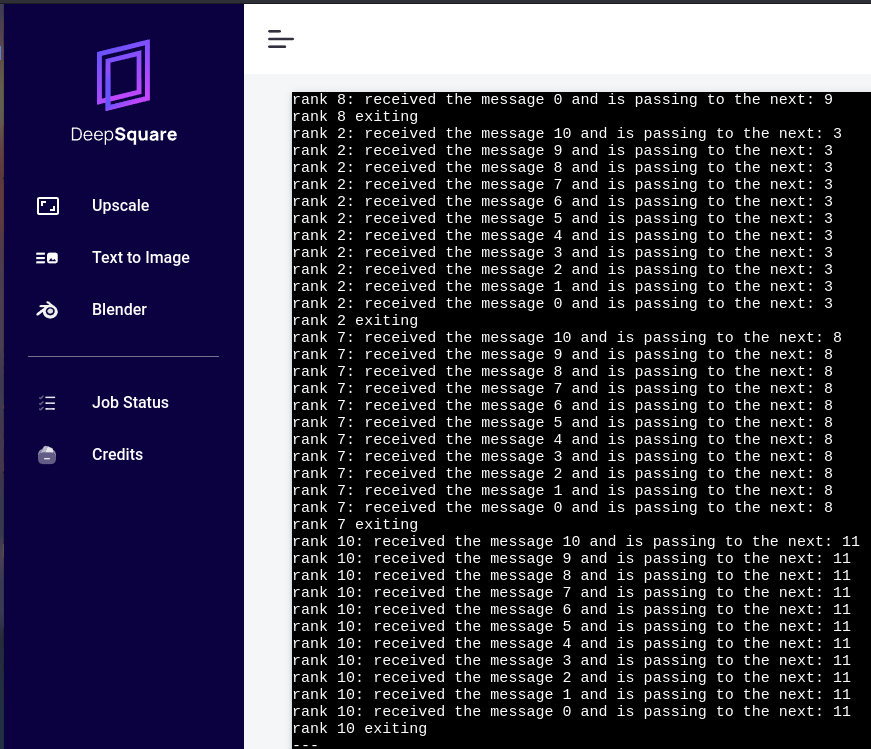
You may see errors like :
--------------------------------------------------------------------------
WARNING: There was an error initializing an OpenFabrics device.
Local host: cn2
Local device: mlx5_2
--------------------------------------------------------------------------
This is because we did not optimize the OpenMPI parameters. The mlx* devices are Mellanox devices and prefer the Unified Communication X (UCX) point-to-point messaging layer (pml). We recommend this tech talk for a better understanding. To tune OpenMPI, you can use environment variables like this:
## Allow DeepSquare logging
enableLogging: true
## Allocate resources
resources:
## A task is one process. Multiple task will allocate multiple processes.
tasks: 16
## Number of cpu physical thread per process.
cpusPerTask: 1
## Memory (MB) per cpu physical thread.
memPerCpu: 1024
## GPU (graphical process unit) for the whole job.
gpus: 0
## Load environment variables
env:
## Configure point-to-point messaging layer to use UCX.
- key: 'OMPI_MCA_pml'
value: 'ucx'
## Configure the byte transfer layer. The "^" prefix means "to exclude". vader, tcp, openib and uct have been excluded.
## vader being the shared-memory transport. It is recommended to not use any of the BTL when using UCX.
## UCX already uses its own transports (see ucx_info -d).
- key: 'OMPI_MCA_btl'
value: '^vader,tcp,openib,uct'
## The job content
steps:
## The steps of the jobs which are run sequentially.
- name: Run the circle program
run:
command: ./main
workDir: /app
resources:
## Launch 16 processes
tasks: 16
## Run in a container containing the example
container:
image: deepsquare-io/mpi-example:latest
registry: ghcr.io
Next steps
Great job on completing the inter-process communication task using OpenMPI on DeepSquare! You've effectively used multiple processors for synchronized communication - a significant milestone in high-performance computing.
Next, we venture into storage management. Data science projects on HPC often involve large-scale data processing. So, you'll learn how to manage datasets as inputs and outputs, a critical skill to leverage the full potential of the DeepSquare platform.